X
Contact Us
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
219 Design offers a 2-Day Workshop called Essential Modern Software Infrastructure for leaders looking for help setting up their software team for optimal success. Kelly Heller and I put together this handy 4-part guide on How to Build Your Software Infrastructure Team for people who want to do it themselves or get a sneak peek of what the workshop covers. In part one, we shared a few core principles we live by here at 219 Design that help us deliver great code. Parts two – four will cover practical applications of those principles across areas such as code reviews, testing, and processes. Included throughout are reading recommendations for further discussion on every topic.
It’s fairly easy to find tales from “ye olden days” of computing wherein only one person at a time could integrate code into the mainline codebase. Antiquated methods for regulating exclusive access could be as crude as “holding the patch pumpkin”. (The patch pumpkin is a stuffed toy, and the rules for integration stated that you must not integrate code unless you held the pumpkin at your desk.)
Allowing contributions in parallel from multiple software engineers provides obvious gains. To achieve this, the use of a version control system is the bare minimum cost of entry. Good news: Git is free!
In Part One of this series, we laid out our guiding principles. Here, in Part Two, we will show how to use Git in service to the principles of knowledge sharing, tight feedback loops, ABA (“Always Be Automating”), and the never-ending fight against complexity.
Readers who already know a little (or a lot) about Git might fear that Git itself is sufficiently complex to mire a team in a pit of complexity. Undeniably, there is a learning curve to confront. However, getting beyond the curve is worth it. There is a reason why thousands of projects have migrated from SVN to Git, and none of them have migrated back!
When teams first witness the power and flexibility of Git, they tend to go overboard creating a proliferation of branches. Keep the following in mind: Git makes branching “cheap” … but merge conflicts are still hard. The simplest way to minimize merge conflicts is to avoid long-lived branches (except for the singular main branch, of course).
On the other hand, do encourage team members to use as many “personal sandbox branches” as they see fit. Allowing (and encouraging) team members to upload their draft branches is an easy way to achieve cloud backup of all your in-progress work in case anyone’s workstation fails. Commit small, and commit often for the best results. Short, clear commit messages go hand-in-hand with atomic commits and set the stage for your reviewers.
There are many GUI(s) for use with Git, but don’t forget that gitk (a basic Git GUI) is included out-of-the-box.
A repository contains the entire history of the project. Each time you git clone a repository, a new repository is created.
A branch contains one working set of the files in the repository. Each repository has a default branch (typically “main” or “master”) that is checked out when the repository is cloned.
A remote is another repository your repository knows about. Typically, your local repository will only know about a remote named “origin”, which is the repository it was cloned from.
Git fetch reads from origin and makes sure that the local repository knows about all of the changes that have happened in origin. Does not update the local copy.
Git pull does a fetch and also merges changes from the “upstream branch”, which corresponds to the currently checked out branch. Git pull is a heavy-handed compound command that begins by doing the same work as a git fetch, but then does additional work. Learners are often taught about git pull straight away and only taught about the fetch command later. We encourage you to learn them at the same time, to get a better understanding from the start, and to possibly lose some “fear of the unknown” as early as possible.
Git push transmits changes from your local branch to the “upstream branch” on origin.
Git add adds local changes to the stage. The stage is an intermediate area you can use to determine what will be included in the next commit. Not all of your changed files (or even all of your changes within a file) need to be committed at once. Using the stage wisely lets you split work you may have done at the same time into logically distinct commits.
Git commit creates a commit from the files in the stage. At this point, only your local repository knows about the changes. Learners must keep in mind that a commit must be followed by a push in cases where you wish to share your changes with the team.
Merge introduces a “merge commit” every time you merge (see images). Conflicts are resolved in the merge commit. If there are no conflicts, then the merge commit is more like a signpost that simply links to the two predecessors being merged, with no actual code changes listed in the merge commit itself.
Squash merge is a variation on merge commit where all commits on a branch are “squashed” into a single commit when merging back to the remote. Squashing is a polarizing topic. More on squashing below.
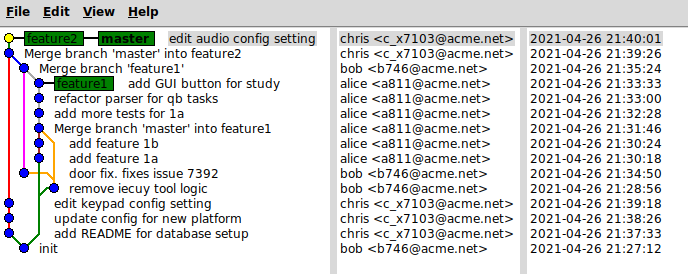
Rebase/Fast-forward keeps a simple git history (see images). When you pull from a remote branch, it takes your local changes (since the last time you pulled), stores them, pulls the changes from the remote, then replays your changes. You have to fix conflicts along the way (generally for each commit).
If you imagine for a moment that your whole codebase is one giant document, then rebasing can be explained via analogy like so: You had access to yesterday’s edition of the document, and you inserted some new paragraphs. Overnight, your co-worker published a new, official edition of the document. To “rebase”, you set aside everything you were working on yesterday, you download the new edition of the document, and then you re-insert your paragraphs (written yesterday) into today’s edition of the document. It is a bit like a “do over”, but usually (thanks to features in Git) it can happen seamlessly and automatically without you actually feeling like you are re-writing those same paragraphs.
Conceptually, one can argue that the rebase tactic keeps each contributor more accountable for staying up-to-date. To continue using the “codebase-as-document” metaphor: if you choose to merge (not rebase), then your new paragraphs will be spliced into the latest document no matter what. If you instead choose to rebase, you have the opportunity to more closely consider the current state of the latest “officially published” document, and reconsider whether your proposed paragraphs still make sense. In short, a policy of rebasing your work before pushing it out to the team prevents contributors from getting “tunnel vision” about their contribution and losing sight of the latest big picture.
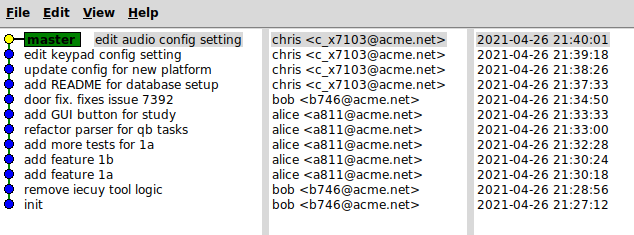
Squashing is a polarizing concept. Squashing is another way to keep the commit history sparse. However, it is an extremely crude method of “cleanup”. Engineers with good commit habits will be annoyed by policies that require use of git squash. Best practices specify to make changes in small steps, such that each step is as self-evidently correct as possible. This leads to small commits with crystal clear commit messages. Squashing reduces any number of such commits to one agglomerated change that bears one large commit message.
Certain code review processes and code review UI(s) are not sophisticated enough to support better options than squashing your work. In these cases you may be obligated to squash in order to not fight against your review tooling.
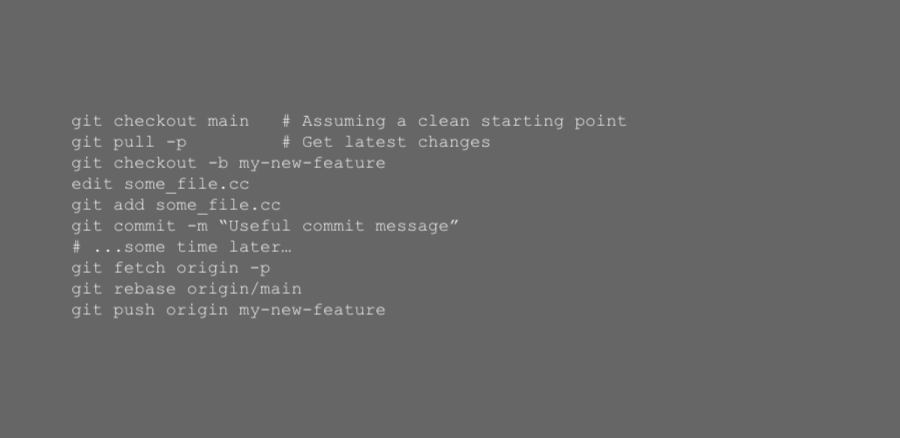
Typical workflow using rebasing:
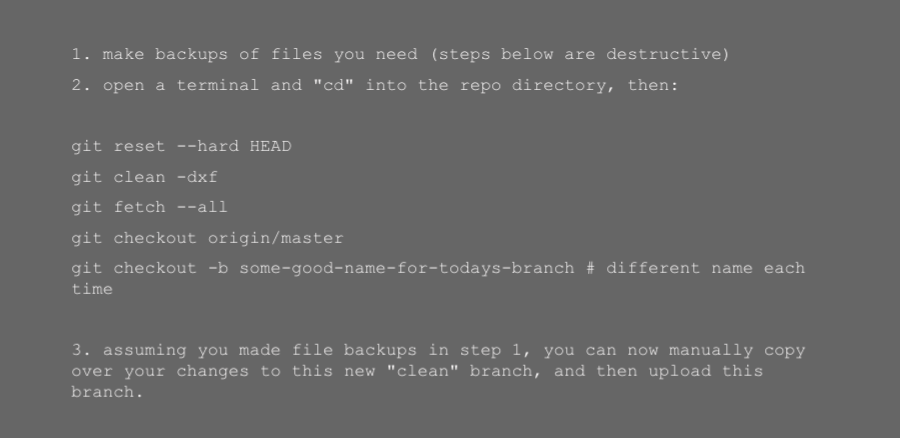
If your local git checkout is a total mess and you cannot figure out how to put it into a state where you can happily push/pull/merge/etc, here is the “nuclear option” that always works:
Simple commit message policy, by GoLang team
Git process that works – say no to GitFlow
Please Stop Recommending Git Flow
Studies show that code review correlates with code quality, but experience demonstrates that it is also a sociological minefield. Watch out for one-up-manship, turf wars, stagnating progress, bullying, and hazing.
Deliberately set your intention regarding code review. The number one goal is probably to prevent bugs. Periodically check in on your process and see if this has remained the driving goal.
Reviewing for stylistic elements that could be better enforced by automated tooling is a drain on morale and a waste of time. Automate those code-style checks! i.e. Humans should not do code-style checks.
Refine your review process to maximize throughput of new work getting into production. Work hard not to block small commits in review. You want to incentivize small commits!
Ideas for maximizing throughput include: clearly label commentary as “just an FYI – no change needed” (where applicable); in the absence of bugs, let the author merge, and extend them the trust that their very next work will be the minor refactor you suggested during the review. Alternatively, let the author merge, and let the reviewer do the suggested minor refactor, and have the original author approve.
Fluency with Git can take a little time. This is time well spent. With a comprehensive version history attached, your repository becomes much more than just folders of code. For the FDA (or other auditing bodies), your repository is evidence of project stewardship. It provides traceability and rollback. It allows any interested team-member to probe the code forensically or (if you like) archeologically. Many commits can be referred back to and reread as “mini cheatsheets” demonstrating such things as the proper syntax for adding a new option to your system configuration file. In short: the learning curve is finite, but the benefits go on and on!
Stay tuned for How to Build Your Essential Modern Software Infrastructure Team Part 3 in which we place the code repository in a larger context supported by continuous integration.
Keep Calm and Automate On. And call us if you get flummoxed along the way!